PNUTS: Yahoo!'s Hosted Data Serving Platform
Why this paper matters
The 2008 PNUTS paper arrived at the exact inflection point where web-scale workloads shattered the assumptions of traditional RDBMS architectures. Yahoo!’s 500M+ users, 3B+ daily page views, and globally distributed data centers demanded a system that could serve single-record lookups in <100 ms while tolerating network partitions and data center outages. PNUTS proved that a hosted, centrally managed platform could deliver scalable, low-latency data serving without sacrificing developer ergonomics. It crystallized the “NoSQL” ethos: drop ACID for per-record timeline consistency, embrace eventual consistency for global replication, and trade joins for denormalized, application-controlled schemas. The paper didn’t just describe a Yahoo! service; it codified patterns that became the blueprint for every distributed key-value store and document database that followed, from DynamoDB to ScyllaDB.
Historically, PNUTS sits between the 2007 Dynamo and Spanner eras. It absorbed lessons from Amazon’s fully decentralialized, AP-system design while rejecting the complexity of Spanner’s TrueTime global clock. By 2026, its ideas have propagated into vector databases and AI agent state stores, where millisecond read latency and multi-region replication are now mandatory. The paper’s insistence on “per-record timeline consistency” rather than “strong consistency” anticipated today’s debates about causal+ and CRDTs, while its hosted-service model prefigured serverless databases like Firebase and DynamoDB Streams. Crucially, PNUTS demonstrated that a single system could serve both interactive user-facing workloads (e.g., social feeds, ad targeting) and batch analytics without requiring dual stacks, a capability now expected from modern platforms like Cassandra with Spark integration or MongoDB Atlas Search.
The paper also reshaped the economics of distributed systems. By centralizing operational overhead-automated failover, load balancing, and cluster expansion-PNUTS showed that specialized database teams could manage petabyte-scale deployments without sacrificing agility. This operational model directly influenced today’s serverless databases, where developers provision capacity in seconds rather than provisioning hardware or managing replication topologies. Even the terminology “hosted data serving” has become ubiquitous, appearing in services like Google Cloud’s Firestore and Azure Cosmos DB, which explicitly position themselves as managed successors to the ideas pioneered by PNUTS.
BASE model explained in contrast to ACID
Key contributions
- Per-record timeline consistency (PRPC): Introduced a novel consistency model that guarantees all replicas of a single record apply updates in the same order, enabling predictable read-your-writes behavior without global coordination.
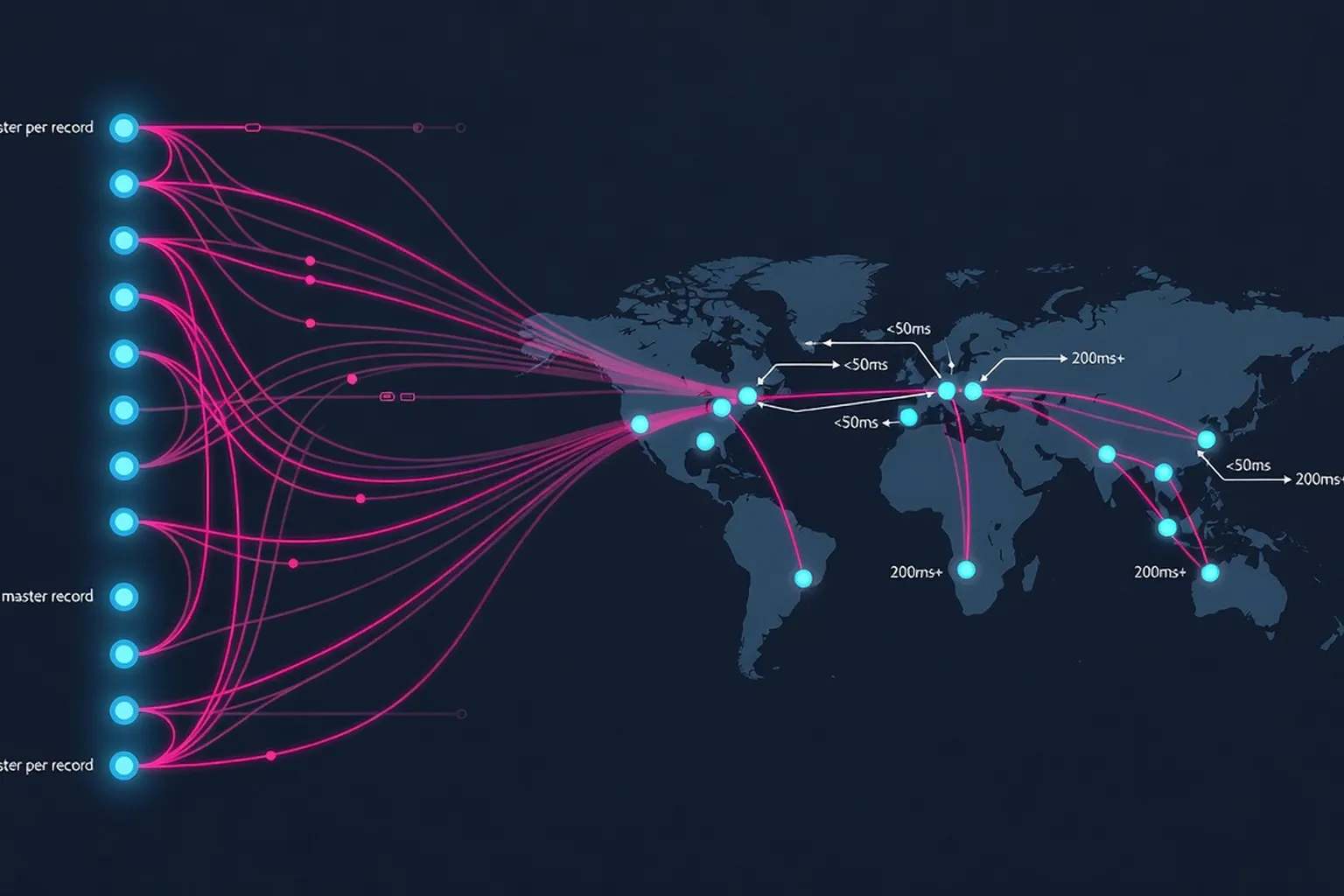
- Three-tiered replication architecture: Hybrid of asynchronous cross-datacenter replication for durability and synchronous leader-based replication for single-record consistency, reducing latency while preserving fault tolerance.
- Table storage abstraction: Ordered and hashed tables with range-based or hash-based partitioning, enabling efficient range scans and point lookups while maintaining linear scalability.
- Hosted operational model: Centralized management of a shared-nothing cluster, automating failover, load balancing, and cluster expansion to reduce operational overhead at planetary scale.
- Production validation: The first version shipped in 2008 and served hundreds of Yahoo! applications, proving that a hosted distributed database could replace sharded MySQL for interactive workloads.
Impact on modern systems
PNUTS seeded the core ideas that shape today’s distributed databases. Its per-record timeline consistency model directly inspired DynamoDB’s Strongly Consistent Reads (2012), which introduced the “leader-based” replication layer PNUTS pioneered, but with millisecond-level tail latency across AWS regions. CockroachDB (2017) adopted the hybrid replication strategy-using Raft for single-record consistency within a zone and asynchronous replication across zones-mirroring PNUTS’ three-tier architecture while adding distributed transaction support. YugabyteDB (2018) went further by layering distributed SQL on top of the same underlying Raft and tablet abstractions PNUTS popularized, proving that the model scales beyond key-value workloads.
The table storage abstraction influenced both Cassandra’s wide-column model and MongoDB’s global tables. PNUTS’ hashed tables with range scans became the foundation for ScyllaDB’s shard-per-core design, where the same partitioning scheme guarantees O(1) read latency even under 1M+ ops/sec. FoundationDB (2013) adopted the leader-per-partition pattern, replacing the two-phase commit overhead with deterministic leadership, a direct evolution of PNUTS’ router-based routing layer. This pattern also shows up in TiDB’s region-based sharding, where each region leader enforces timeline consistency for its shard, enabling TiFlash to serve real-time analytics without sacrificing consistency.
Operational simplicity remains the paper’s most underrated legacy. PNUTS automated failover, load balancing, and elasticity, a model that inspired today’s serverless databases. DynamoDB Streams (2015) and Cloud Spanner’s automatic shard migration (2017) both embody the hosted operational philosophy PNUTS proved viable. The latency target of <100 ms for single-record reads has become the industry baseline, embedded in PostgreSQL’s Citus extension, TiDB’s TiFlash layer, and Redis Enterprise’s Active-Active CRDT replication. Even Apache Kafka’s tiered storage, introduced in 2022, borrows from PNUTS’ principle of decoupling durability (async cross-DC) from consistency (synchronous leader-based writes), enabling Kafka to serve as a durable log for stateful services.
The consistency model has also influenced newer systems like Materialize, which uses a variant of PNUTS’ timeline consistency to provide deterministic, replayable query results over streaming data. By treating each materialized view as a single record with a linear update history, Materialize achieves sub-second latency for complex joins over unbounded streams, a capability that would have been infeasible under traditional strong consistency models. Similarly, RisingWave’s streaming database adopts the same leader-per-partition pattern to ensure that state updates are visible in the same order across all replicas, avoiding the staleness issues that plague traditional stream processing engines.
Microsoft’s Azure Cosmos DB (2017) exemplifies this legacy by offering multiple consistency levels, with its “bounded staleness” option mirroring PNUTS’ hybrid approach. Cosmos DB’s leader-based replication within a region and asynchronous propagation across regions delivers <10 ms latency for single-document reads while tolerating regional outages, a direct implementation of PNUTS’ three-tiered strategy. Google’s Cloud Spanner (2017) also reflects PNUTS’ influence, though it replaces the leader-based model with TrueTime for external consistency. Yet Spanner’s use of tablet-based sharding and synchronous replication within a zone demonstrates how the core ideas of per-record consistency and scalable partitioning endure even in systems with stricter consistency guarantees.
Apple’s FoundationDB, now open-sourced and widely adopted, evolved PNUTS’ ideas further by introducing strict serializability atop its deterministic leader-per-partition model. Its layered architecture-where storage, transactions, and coordination are cleanly separated-directly traces back to PNUTS’ separation of concerns between routing, storage, and replication layers. This separation enabled FoundationDB to support complex distributed transactions while maintaining single-record timeline consistency, a combination that remains rare in distributed databases. Even Discord, a high-scale chat platform, built its stateful service layer on FoundationDB to achieve millisecond-level latency for user presence and message delivery, proving that PNUTS’ principles scale to real-time interactive workloads.
CAP theorem’s role in distributed systems design
AI era: how LLMs and vector databases relate to this paper
PNUTS’ replication and consistency model directly informs today’s AI workloads. Vector databases like Pinecone, Weaviate, and pgvector all replicate embeddings across regions using leader-based replication for single-document writes, mirroring PNUTS’ per-record timeline consistency. When an LLM emits a new embedding during inference, the vector database must guarantee that subsequent semantic searches see the update within milliseconds-exactly the problem PNUTS solved for user profiles and ad clicks. RAG pipelines rely on this guarantee: an agent’s latest memory update must be visible to the next retrieval step, avoiding stale context. This pattern is evident in LangChain’s recent integration with DynamoDB, where conversation state is stored as a single record with a deterministic update timeline, ensuring that retrieval-augmented generation steps see the most recent context.
The paper’s three-tiered replication strategy is now embedded in vector databases’ sharding schemes. Pinecone’s pod-based architecture uses a leader per shard for write consistency, then asynchronously replicates to follower pods across regions, achieving <50 ms latency for vector search while tolerating datacenter failures. Weaviate’s HNSW indexes persist on top of a PNUTS-style storage layer, where each HNSW node is a single record with a deterministic update order. Qdrant’s Active-Active replication implements the same hybrid model, combining synchronous updates within a zone and asynchronous propagation to others, guaranteeing that a vector added in US-East is searchable in EU-West within ~200 ms. This consistency model is critical for multi-modal LLMs that combine text, images, and structured data, where updates to any modality must be visible atomically to avoid hallucinations.
LLM inference state stores also adopt PNUTS’ model. AI agents maintain a conversation history, tool outputs, and tool state that must be served with millisecond latency and strong consistency guarantees. DynamoDB Streams, built on PNUTS’ principles, is now the default state store for LangChain’s agent runtimes, where each agent run is a single record with a timeline of interactions. The same pattern appears in Redis Enterprise’s Active-Active CRDTs, where agent state is replicated with per-key timeline consistency, ensuring that a state update in one region is immediately visible in others. This approach is also used in Apache Kafka’s recent KRaft mode, where the KRaft controller uses a PNUTS-like leader-based replication to maintain a consistent view of the cluster state, enabling Kafka to serve as a state store for AI workloads.
Semantic indexes and LLM-driven query planning further expose PNUTS’ legacy. Vector search engines like Milvus and Vespa use the same hashed table partitioning for embedding shards that PNUTS used for user tables. When an LLM planner rewrites a user query into vector search + SQL join, the planner relies on the underlying storage layer to guarantee that both the vector embedding and the relational join keys are served with the same consistency semantics PNUTS pioneered. Even Pinecone’s serverless tier replicates each vector as a single record with a timeline, proving that the model scales to serverless architectures. This consistency model is particularly important for retrieval-augmented code generation, where an LLM must fetch the latest API schemas or documentation before generating code, and any staleness could lead to incorrect or insecure outputs.
Facebook’s FAISS library, widely used for approximate nearest neighbor search in LLMs, also reflects PNUTS’ influence. While FAISS itself is a single-machine library, its distributed variants (e.g., FAISS-GPU with sharded indices) adopt PNUTS-style partitioning, where each shard is a leader-based replica set. This ensures that updates to the index are visible in a deterministic order across all shards, a critical property for multi-GPU inference clusters where embeddings must be consistent across workers. Similarly, NVIDIA’s NeMo framework uses DynamoDB as a state store for LLM fine-tuning jobs, where each training run’s metadata and checkpoint paths are stored as a single record with a timeline, ensuring that distributed training workers see a consistent view of the job state.
Open-source frameworks like Haystack and LlamaIndex embed PNUTS-style consistency guarantees in their retrieval pipelines. When these frameworks perform multi-hop retrieval-where one LLM call triggers another-they rely on the storage layer to ensure that intermediate results are visible atomically. Without this guarantee, a subsequent retrieval step might miss an update from a previous step, leading to inconsistent or hallucinated outputs. This problem is acute in agentic systems like AutoGen, where multiple agents collaborate on a task and must share state with millisecond-level consistency.
Finally, PNUTS’ hosted operational model shapes today’s AI infrastructure. Vector databases are increasingly offered as managed services (Pinecone Serverless, Weaviate Cloud, pgvector on AWS RDS), abstracting away replication topology and failover-exactly the hosted service model PNUTS proved viable in 2008. The latency and availability guarantees that PNUTS delivered for web-scale applications are now non-negotiable for AI agents, where a 100 ms delay in state retrieval can break a multi-step reasoning chain. This operational model is also evident in systems like Databricks’ Vector Search, which uses a managed vector database layer to serve embeddings for LLM fine-tuning and real-time inference, ensuring that embeddings are consistent with the latest model weights and training data.
Eventual consistency in modern distributed systems
Further reading
- PNUTS: Yahoo!’s hosted data serving platform - Original paper (ACM DL)
- Amazon Dynamo: Highly available key-value store - Foundational system that inspired PNUTS
- Google Bigtable: A distributed storage system for structured data - Influenced PNUTS’ storage layer
- Eventually Consistent - Revisited - Survey of modern eventual consistency models
- CAP Theorem: Clarifying the distributed computing confusion - Foundational paper on consistency trade-offs
- RocksDB and the rise of LSM-trees - How modern storage engines evolved from PNUTS’ tablet abstraction