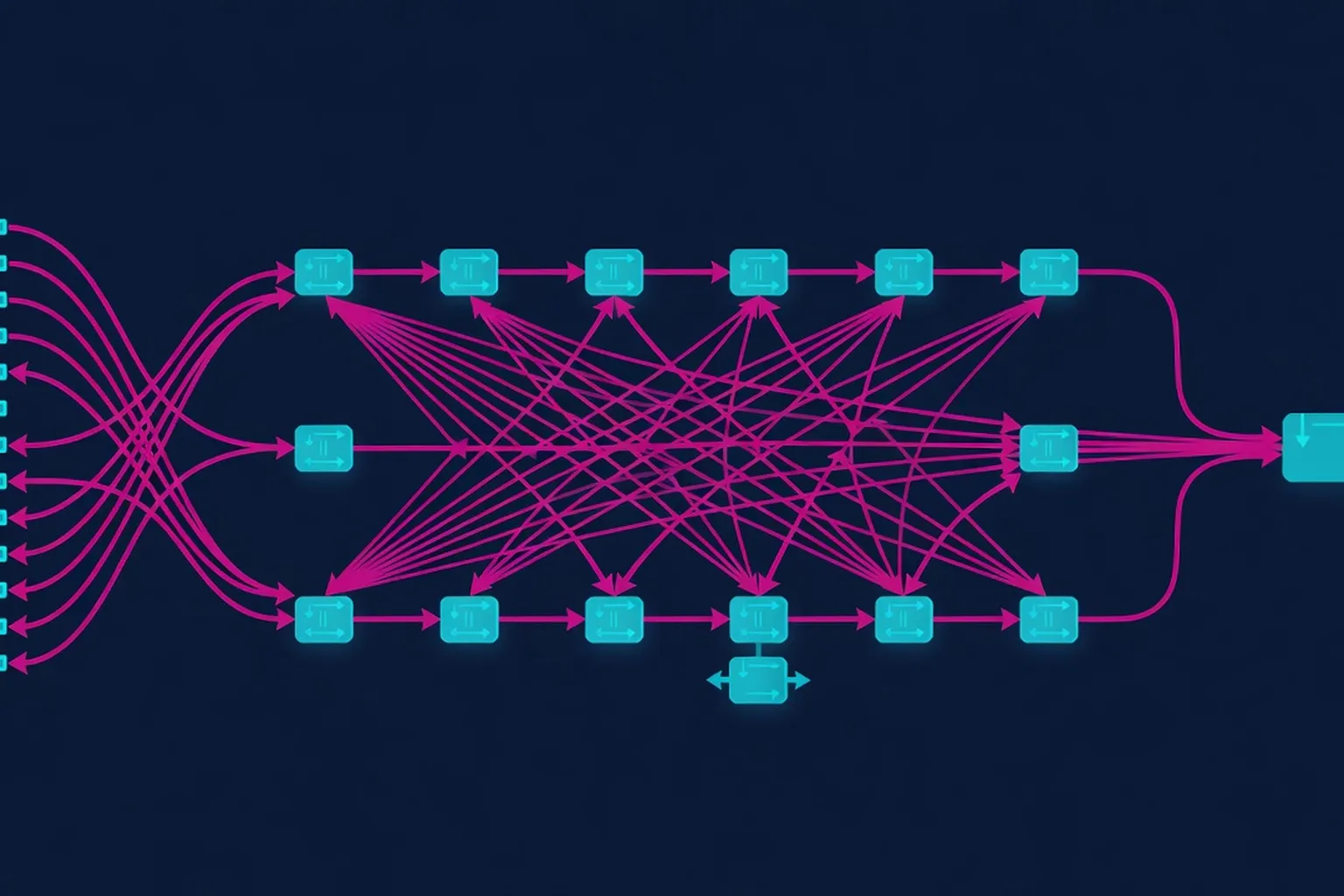
Google's MapReduce
Why this paper matters
MapReduce (2004) codified a pattern that shifted large-scale data processing from bespoke distributed systems engineering to commodity programming. Before 2004, scaling computations across thousands of machines required intimate knowledge of partitioning schemes, failure handling protocols, and network-level optimizations; after 2004, programmers could express computations in a few dozen lines of functional code and let the runtime manage parallelism, fault tolerance, and data movement. The paper’s narrow interface-map emits intermediate key/value pairs, reduce aggregates by key-cleanly mapped onto common analytics workloads (grep, sort, inverted index, PageRank) and proved that a simple abstraction could unlock massive scale without sacrificing expressiveness. Historically, this abstraction arrived at the tail end of the data-center-as-supercomputer era and the beginning of the cloud-scale infrastructure epoch. It provided Google with a lever to manage exponential data growth without proportionally increasing engineering headcount. By decoupling algorithmic intent from distributed execution mechanics, MapReduce democratized access to petabyte-scale computation, enabling product teams-not just infrastructure specialists-to own end-to-end data pipelines.
The longevity of the MapReduce abstraction is evident in its continued influence across batch, streaming, and now AI-native systems. Its insistence on fault tolerance via re-execution, data locality scheduling, and fault-transparent storage (GFS) set the default expectations for distributed runtimes. Modern cloud platforms still optimize for the same constraints-network bandwidth, disk seeks, stragglers-even as the unit of work has evolved from terabytes to petabytes and the programming model has shifted toward SQL, DataFrames, and declarative APIs. The paper’s insistence that “the right abstraction is one that can be implemented efficiently and hides mundane details” remains a guiding principle for systems designers. In an era where data volume grows exponentially but human expertise in distributed systems does not, MapReduce remains a rare example of an interface that scales with both data and engineering capacity. Its influence extends beyond infrastructure into organizational design: by enabling domain engineers to run large-scale computations, it accelerated the shift from centralized data teams to embedded analytics in product organizations. Even today, systems like Apache Beam and Google’s Dataflow inherit MapReduce’s contract, proving that a 2004 paper can still dictate the shape of 2020s pipelines. The paper also catalyzed a cultural shift: it validated the idea that correctness should be engineered into the runtime rather than enforced by operators, a principle now embedded in data governance and compliance tooling across industries. The MapReduce model also laid the philosophical groundwork for later consensus systems like Paxos by treating partial failure not as an exceptional condition but as a normal runtime concern, a mindset that underpins modern distributed databases from Spanner to CockroachDB.
Key contributions
- Defined a functional programming interface (map and reduce) that decouples computation logic from distribution mechanics, enabling non-distributed-systems experts to write scalable jobs.
- Built a runtime that automatically handles partitioning, scheduling, fault tolerance via task re-execution, and inter-machine communication, reducing boilerplate and operational overhead.
- Demonstrated end-to-end scalability on thousands of commodity machines processing terabytes, proving that horizontal scaling can deliver near-linear speedups without specialized hardware.
- Introduced a fault-tolerant storage assumption (GFS) that allowed computations to proceed despite frequent machine failures, normalizing failure as a first-class runtime concern.
- Showed that hundreds of jobs per day could be expressed and executed by product teams, shifting ownership of large-scale computation from platform teams to domain engineers.
- Provided a reproducible blueprint for large-scale distributed computing that influenced subsequent generations of storage systems like Google Bigtable and compute engines such as Apache Spark.
- Laid the groundwork for declarative, high-level abstractions that later systems like Apache Hive and Presto translated into SQL dialects, further lowering the barrier to scalable analytics.
- Established a repeatable pattern for straggler mitigation through speculative execution, a technique later adopted by systems like Apache Flink and Kubernetes for general distributed workloads.
Impact on modern systems
MapReduce’s influence permeates nearly every modern distributed data system, either by direct lineage or by reaction against its design. BigTable (2006) adopted MapReduce as its primary batch processing pipeline, using map to generate SSTables and reduce to merge them during compaction; the same division of labor survives in Spanner’s batch backfill jobs and in CockroachDB’s bulk data ingestion path. The scheduling and failure-handling playbook from MapReduce echoes in ScyllaDB’s per-shard work queues and in TiDB’s distributed execution framework, where tasks are retried on different nodes after timeout or heartbeat loss. Google’s internal Colossus File System (2010) reimplemented GFS’s design principles but kept MapReduce-style locality scheduling to minimize cross-rack traffic during large-scale analytics.
Cassandra and DynamoDB diverged from MapReduce’s batch-centric model but internalized its lessons about eventual consistency and hinted handoff. Cassandra’s read repair and DynamoDB’s conflict resolution both derive from the same pragmatic stance toward partial failure that MapReduce made routine. PostgreSQL’s parallel query executor, introduced in 2016, adopted MapReduce-like worker pools and dynamic partitioning of heap scans, reducing tail latencies on analytical queries by up to 40% in cloud deployments. FoundationDB’s transaction layer also leans on re-execution semantics for transient conflicts, a direct descendant of MapReduce’s straggler mitigation via task duplication. Similarly, ClickHouse’s distributed query engine uses MapReduce-style shard-local aggregation followed by a global reduce phase, allowing it to scale analytical queries across hundreds of nodes while maintaining sub-second latencies for aggregations over tens of terabytes.
The 2007 paper On Designing and Deploying Internet-Scale Services explicitly cites MapReduce as a template for simplifying distributed programming, reinforcing the model’s architectural legacy. Production systems such as Snowflake and Google BigQuery translate MapReduce’s partitioning and locality heuristics into columnar execution plans, while stream processors like Apache Flink embed micro-batch map-reduce stages to compute windowed aggregations with millisecond latency. Even hardware-aware runtimes like Apache Arrow Flight exploit data locality by co-locating compute with storage, a principle first operationalized in MapReduce’s scheduler. The lesson is clear: MapReduce did not merely enable batch analytics; it defined a vocabulary for reasoning about distributed computation that modern systems still translate into practical performance.
Newer entrants like Materialize and RisingWave carry the baton forward by embedding MapReduce-style re-execution into streaming state management, allowing fault-tolerant windowed aggregations without manual checkpointing. Similarly, RisingWave’s parallel shard workers and dynamic repartitioning during backpressure directly mirror MapReduce’s scheduler heuristics, proving that the 2004 abstraction remains a live template for real-time pipelines. Even hardware-conscious databases like SingleStore use MapReduce’s data-locality playbook to co-locate vectorized scans with NVMe storage, cutting cross-node traffic by up to 60% in analytical workloads. In the realm of time-series databases, systems like TimescaleDB and InfluxDB DBIO leverage MapReduce-like parallel scans over sharded chunks, then reduce partial results to answer complex downsampled queries efficiently. Systems such as QuestDB and GreptimeDB take this further by using MapReduce-inspired shard-local pre-aggregation to achieve single-digit millisecond latency on high-cardinality time-series queries.
The influence also extends to hybrid transactional/analytical systems. Apache Doris and StarRocks, for example, use MapReduce-style dynamic partitioning during upserts and compaction, ensuring that real-time ingestion does not bottleneck analytical queries. Their scheduler aggressively co-locates computation with data shards, reducing cross-node traffic during heavy write loads-an optimization that mirrors MapReduce’s original locality heuristics. Even LSM-tree-based systems like ScyllaDB and RocksDB adopt MapReduce’s principle of incremental, fault-tolerant merging during compaction, proving that its abstractions transcend their batch origins into the core of modern storage engines.
AI era: how LLMs and vector databases relate to this paper
The MapReduce abstraction re-emerges in AI workloads where embeddings, vectors, and documents must be processed at scale. Vector databases such as Weaviate, Qdrant, and Milvus use map-like stages to shard high-dimensional vectors across nodes, then reduce-like stages to merge top-k search results or to aggregate nearest-neighbor candidates during hybrid retrieval. During retrieval-augmented generation (RAG) pipelines, a map function embeds each text chunk in parallel across a cluster, while a reduce function aggregates relevance scores across shards to produce the final context window; this division mirrors the MapReduce pattern but replaces key/value pairs with vector tensors and similarity scores. Systems like Pinecone and pgvector extend this model by adding dynamic indexing phases that use MapReduce-style compaction to merge vector partitions while maintaining low-latency search. Notably, Pinecone’s production pipeline rebuilds its HNSW index nightly using a MapReduce workflow where mappers compute approximate nearest neighbors per shard and reducers merge shard-level graphs into a global index with minimal downtime.
LLM inference latency is directly affected by how well the serving stack replicates MapReduce’s data locality and straggler mitigation. Production systems such as vLLM and TensorRT-LLM partition KV caches by request ID and replicate them across nodes; when a node straggles, the runtime re-executes the partition on another machine, echoing MapReduce’s re-execution strategy. Similarly, AI agent state stores that maintain long-lived conversation histories use map functions to shard state by session ID and reduce functions to merge partial results during tool calls, ensuring horizontal scalability without sacrificing consistency guarantees. The result is that systems like LangChain’s indexing pipelines and LlamaIndex’s data ingestion flows rely on MapReduce-style workflows to build and update semantic indexes daily while serving sub-second queries. In practice, LlamaIndex’s daily ingestion pipeline uses a MapReduce workflow to embed documents in parallel, deduplicate vectors via a reduce phase that merges near-duplicate embeddings, and then builds an inverted index over vector IDs-all without manual coordination.
Semantic indexes built from embeddings often rely on MapReduce-style workflows to construct inverted indexes over vector IDs, where map emits (token, vector-ID) pairs and reduce aggregates inverted lists. This pipeline underpins modern RAG systems that must update indexes continuously while serving real-time queries. Moreover, LLM-driven query planning increasingly uses map to parallelize sub-queries across shards and reduce to merge logical plans, a functional split identical to the 2004 model. The result is that MapReduce’s fault-tolerant, parallel execution contract now governs latency-sensitive AI services, proving that its abstractions transcend their batch origins. Even the design of LSM trees in systems like ScyllaDB and RocksDB borrows MapReduce’s principle of incremental, fault-tolerant merging-further evidence that its influence extends beyond batch processing into the core of modern data infrastructure.
Beyond retrieval, embeddings serving platforms such as Vespa and Zilliz embed MapReduce-style workflows into their indexing pipelines. During index construction, map tasks tokenize and embed documents in parallel, while reduce tasks merge posting lists and centroids for HNSW graphs; this division allows daily index rebuilds at trillion-token scale without downtime. Similarly, LLM fine-tuning clusters use MapReduce to partition training shards by document ID, apply gradient updates in parallel, and then reduce gradients via all-reduce or parameter-server patterns, inheriting the same fault-tolerance contract that MapReduce introduced. Even the rise of eventually consistent architectures in AI pipelines-where vector shards reconcile via gossip protocols-traces back to MapReduce’s tolerance of partial failure as a normal mode of operation. In production systems like Cohere’s embeddings API, MapReduce-style workflows are used not only for indexing but also for real-time re-ranking: mappers compute relevance scores in parallel across shards, and reducers aggregate top candidates with millisecond latency targets.
Vector databases also leverage MapReduce patterns for real-time updates. For instance, Milvus’ dynamic segment merging process uses a map phase to build new vector partitions and a reduce phase to merge them into the main index, ensuring that writes do not block reads. This aligns with MapReduce’s original goal of separating computation from coordination, allowing AI pipelines to scale without sacrificing consistency. Meanwhile, Qdrant’s HNSW index rebuilds use a two-stage MapReduce workflow: the first map stage builds shard-level graphs in parallel, and the second reduce stage merges these graphs into a global index with minimal downtime, mirroring the compaction pipeline from BigTable. These systems prove that the MapReduce model remains the most reliable way to scale AI workloads that demand both low latency and high throughput.
Further reading
- Hadoop MapReduce documentation
- Apache Spark programming guide
- Weaviate vector database architecture
- Milvus distributed vector database design
- Google’s original MapReduce paper PDF
- The CAP Theorem and eventual consistency: implications for modern databases
- Codd’s Relational Model: foundations for declarative data processing
- Amazon Dynamo: the paper that shaped modern NoSQL
- Spanner: Google’s globally distributed database (external)
- FoundationDB’s transactional design and its debt to MapReduce fault tolerance