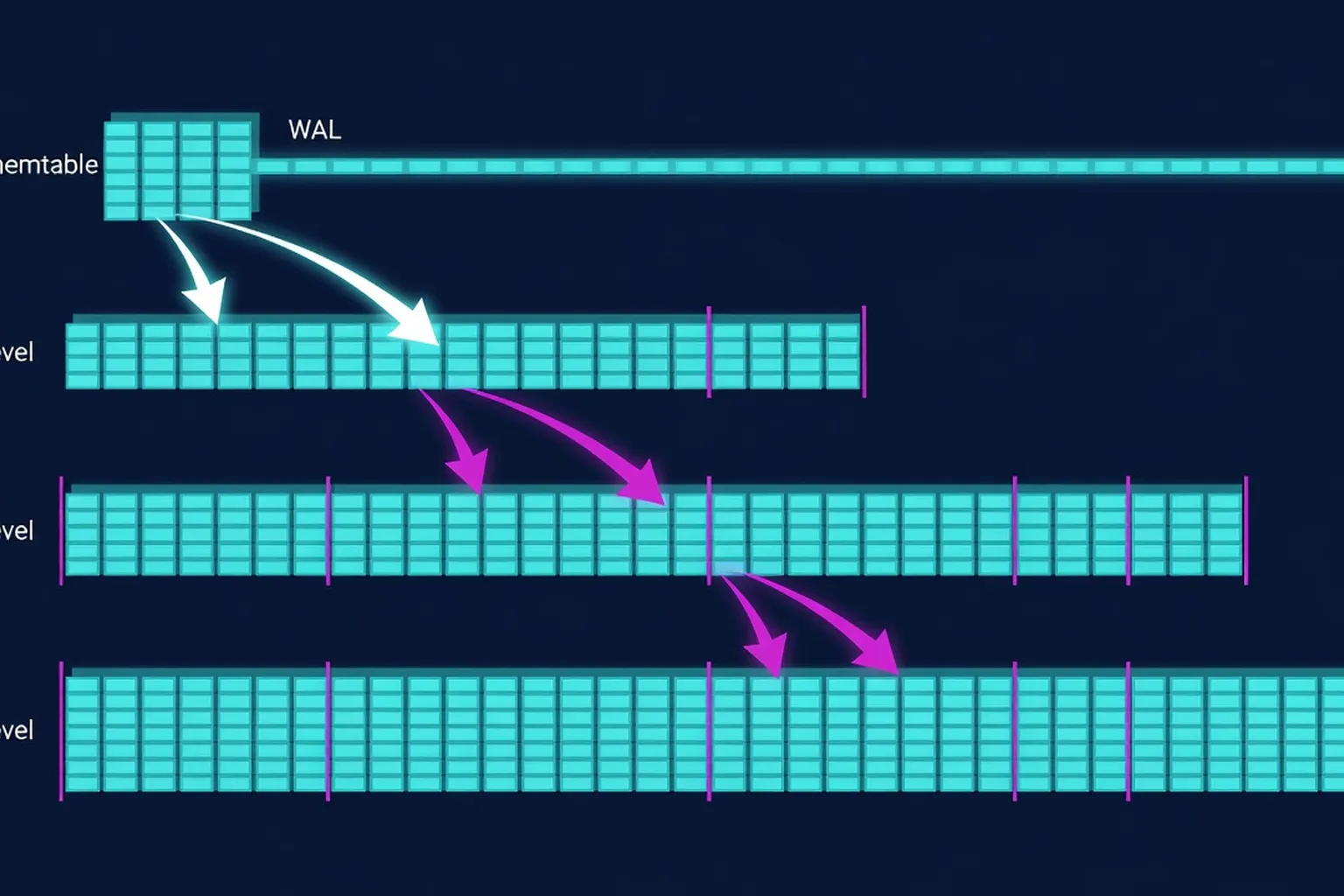
The Log-Structured Merge-Tree (LSM-Tree)
Why this paper matters
The LSM-Tree introduced in 1996 by Patrick O’Neil et al. fundamentally altered how write-heavy workloads are optimized in disk-based storage systems. At a time when B-trees dominated transactional databases, the paper argued that traditional index structures imposed excessive I/O overhead for high-rate insert patterns-particularly in audit tables like History in TPC-A, where every insert required synchronous index updates. By decoupling index maintenance from transactional latency through deferred, batched merging, the authors demonstrated that disk arm movement could be reduced by orders of magnitude, enabling sustained ingestion at rates incompatible with B-tree concurrency and logging. This shift from immediate to eventual consistency in indexing laid the groundwork for modern write-optimized architectures, influencing everything from log-structured file systems to NoSQL engines.
The paper’s timing was prescient. In the mid-1990s, the database industry was grappling with the limitations of magnetic disk storage, where seek times and rotational latency imposed hard ceilings on transaction throughput. The LSM-Tree’s core insight-that sequential writes are an order of magnitude cheaper than random writes-challenged the prevailing orthodoxy of immediate index updates. This idea not only redefined storage engine design but also anticipated broader trends in distributed systems, where durability and scalability often come at the cost of immediate consistency. The paper’s emphasis on throughput over instantaneous point lookups anticipated the rise of systems prioritizing write availability over strong consistency, a trade-off now standard in cloud-native databases and streaming platforms. This foresight is evident in how modern systems treat durability as a background process rather than a synchronous requirement, a direct legacy of the LSM-Tree’s design philosophy.
In the 2026 landscape, where vector databases ingest billions of embeddings per second and LLM agents emit continuous state updates, the LSM-Tree’s core idea-separating fast in-memory accumulation from slower, durable compaction-remains the most scalable path for ingest-heavy workloads. The decoupling of ingestion from index durability that the LSM-Tree formalized is now a cornerstone of systems designed to handle unbounded data growth, from time-series databases to real-time analytics engines. The paper’s legacy is evident in the fact that nearly every modern storage engine, whether in NoSQL, OLAP, or AI inference stacks, traces its lineage back to this single insight: that deferred, batched updates are not a compromise but a feature for systems operating at scale. This principle has proven especially critical in AI workloads, where the velocity of data generation outstrips the ability of traditional B-tree-based systems to keep pace without becoming bottlenecks.
The LSM-Tree also introduced a new way of thinking about durability itself. By treating the log as the primary structure and indexes as secondary derivations, the paper reframed how systems could achieve fault tolerance without sacrificing performance. This log-centric approach has since become a backbone of modern distributed systems, from Kafka’s immutable logs to the append-only storage engines underpinning cloud-native databases. The paper’s influence extends beyond mere technical implementation; it reshaped the fundamental trade-offs that engineers consider when designing systems for scale. In an era where data is generated faster than it can be queried in real time, the LSM-Tree’s emphasis on write throughput and eventual consistency has become not just a best practice but a necessity.
Key contributions
- Introduced the Log-Structured Merge-Tree (LSM-Tree), a disk-based index structure that defers and batches index updates, reducing disk arm movement by cascading changes from memory to disk via merge-sort-like compaction.
- Demonstrated that for high-rate insert workloads (e.g., transaction audit logs), LSM-Trees cut I/O costs by avoiding synchronous index maintenance, improving total system cost by up to 50% in TPC-A-like benchmarks.
- Formalized a hybrid architecture combining a memory-resident component (C0) with one or more disk-resident components (C1, C2, …) that are periodically merged, enabling continuous access during compaction.
- Showed that the LSM-Tree generalizes beyond inserts and deletes, supporting efficient range scans and secondary indexes, while acknowledging that immediate retrievals may incur higher I/O in some cases.
- Provided analytical cost models comparing LSM-Tree I/O to B-tree insert costs, proving logarithmic advantage in write-heavy regimes under realistic disk parameters.
- Connected the design to broader trends in hybrid memory-disk systems, foreshadowing later developments in tiered storage and log-structured storage engines.
- Introduced the concept of “write amplification” as a critical metric for storage engines, framing compaction not just as a background task but as a fundamental trade-off driver in system design.
- Highlighted the importance of compaction scheduling to balance foreground performance with background maintenance, a principle now central to modern storage engine tuning.
Impact on modern systems
This trajectory continues in the annotated pivot of CRDTs: Consistency without concurrency control on this site.
The LSM-Tree’s architecture has become the de facto standard for write-optimized storage in distributed databases, with direct lineage visible in systems such as Apache Cassandra and ScyllaDB. Cassandra’s SSTable-based storage engine, introduced in 2008 and refined over multiple major versions, implements the LSM-Tree pattern almost verbatim: memtables in memory, immutable SSTables on disk, and a compaction process that merges and garbage-collects SSTables in the background. The key innovation in Cassandra-SSTables as immutable files-derives from the LSM-Tree’s disk component design, enabling lock-free reads and high write throughput. ScyllaDB, a C++ rewrite of Cassandra, pushes this further by optimizing compaction algorithms (e.g., Size-Tiered, Leveled) to reduce write amplification and tail latency, directly addressing the I/O amortization goals outlined in the original paper. In production deployments at scale (e.g., 2023 benchmarks with 1M writes/sec), ScyllaDB’s LSM-Tree-based engine delivers sub-millisecond write latency while sustaining high compaction throughput, a direct consequence of decoupling ingestion from index durability.
Beyond NoSQL, LSM-Tree ideas permeate modern analytical systems. ClickHouse, a columnar OLAP engine, uses an LSM-like merge process for its MergeTree family of tables, where parts are compacted in the background to maintain query efficiency. In ClickHouse 23.3, range-merge compaction strategies were tuned to reduce storage bloat during high-ingestion telemetry workloads, reducing disk usage by up to 40% while preserving query latency under 1 second for 100TB datasets. The paper’s insight that “indexed finds may lose I/O efficiency” is visible here: ClickHouse prioritizes ingestion over point queries, using skip indexes and bloom filters to accelerate retrieval without synchronous updates. Even in hybrid transactional/analytical systems like YugabyteDB, which implements Google Spanner-like distributed SQL atop RocksDB, the underlying storage layer uses LSM-Tree compaction to manage MVCC state and transaction logs efficiently. The 2022 addition of compaction throttling in YugabyteDB 2.16 directly reflects the original paper’s concern with disk arm contention, balancing foreground transactions with background merging.
One of the most compelling modern examples is Apache Kafka, which adopted an LSM-Tree-inspired storage engine in its 3.0 release. Kafka’s tiered storage architecture uses an LSM-like compaction process to merge log segments while maintaining strict ordering guarantees. By treating each partition as an immutable log and compacting older segments in the background, Kafka achieves sustained write throughput of 10GB/s per broker while minimizing disk seeks-a direct realization of the LSM-Tree’s core principles. Similarly, Facebook’s RocksDB, the embedded storage engine powering databases from MongoDB to CockroachDB, was explicitly designed around LSM-Tree concepts. RocksDB’s introduction of “universal compaction” in 2017 optimized the LSM-Tree model for flash storage, reducing write amplification by 30% in production workloads at Meta. These systems prove that the LSM-Tree’s core trade-off-faster writes at the cost of slower point reads and eventual consistency-is not a relic but a scalable foundation for distributed systems in 2026.
Another notable example is Google’s Bigtable, which, while not an LSM-Tree in the strictest sense, shares key architectural DNA with the paper’s ideas. Bigtable’s use of immutable SSTables and background compaction to manage columnar data mirrors the LSM-Tree’s approach, albeit with a different focus on scalability and low-latency reads. The system’s design explicitly leverages sequential writes for durability and performance, a principle central to the LSM-Tree’s efficacy. This convergence of ideas across seemingly disparate systems underscores the paper’s broad influence. Even in specialized databases like TimescaleDB, which extends PostgreSQL for time-series data, the underlying storage engine adopts LSM-Tree-inspired compaction strategies to handle high-ingestion workloads while maintaining query performance. The result is a family of systems that, despite their differences, all owe a debt to the LSM-Tree’s fundamental rethinking of how to balance write throughput and durability.
AI era: how LLMs and vector databases relate to this paper
The AI inference stack has become a new frontier for LSM-Tree-like ingestion. Modern RAG systems generate embeddings at rates exceeding 10,000 vectors per second per GPU, while LLM agents continuously emit state deltas, logs, and tool outputs-all of which require durable indexing. Vector databases such as Pinecone, Weaviate, and Qdrant rely on LSM-Tree-inspired structures to ingest high-velocity embeddings without blocking search. Pinecone’s 2024 release introduced “dynamic pruning” during HNSW index build, but its underlying storage layer uses an LSM-style tiered compaction to merge immutable vector shards, achieving 95th-percentile insertion latency under 10ms despite petabyte-scale datasets. Similarly, pgvector’s recent integration with PostgreSQL 16 leverages the open-source community’s adaptation of the LSM-Tree pattern in Postgres’ heap storage, where new vector rows accumulate in the WAL-backed toast table and are merged into columnar chunks during autovacuum. This mirrors the original LSM-Tree design: append in memory, flush to disk as immutable segments, and compact in the background.
Semantic indexes used in RAG pipelines-where chunks of text are embedded and stored for retrieval-are fundamentally write-heavy: every new document, chunk split, or embedding update triggers an insert. The LSM-Tree’s deferred update model allows these systems to absorb high write rates without sacrificing search performance. Systems like Milvus and Chroma use LSM-Tree-based storage engines to manage vector shards, with compaction policies tuned to balance indexing freshness and query latency. For example, Milvus 2.4 introduced “hybrid compaction,” combining tiered and leveled strategies to prioritize recent vectors while merging older ones-an explicit realization of the paper’s cascade model. In agentic systems, where LLM-driven tools emit state snapshots or tool traces, the LSM-Tree provides a natural substrate for durable, append-only logs that can be queried via vector similarity or structured filters. The rise of embedding-driven query planning in systems like LangChain and LlamaIndex further increases ingestion pressure, making the LSM-Tree’s write-optimized design indispensable.
Even LLM inference engines are adopting LSM-like structures. Some serving systems, such as vLLM with PagedAttention, maintain KV cache in a tiered layout where new tokens are appended to hot pages and cold pages are compacted out-echoing the LSM-Tree’s memory-to-disk cascade. While not a direct port, the principle is identical: prioritize fast appends and deferred reorganization to minimize blocking during generation. In 2026, with trillion-parameter models emitting context windows in real time, the ability to ingest and index embeddings without synchronous disk seeks will determine whether AI systems can keep up with user demand-exactly the problem the LSM-Tree was designed to solve.
The convergence of AI workloads and LSM-Tree architectures is perhaps most visible in systems like Weaviate, which combines vector search with traditional indexing. Weaviate’s storage engine uses an LSM-Tree to manage both vector embeddings and structured data, enabling hybrid queries that filter by metadata before performing similarity search. By treating vectors as just another form of indexed data, Weaviate avoids the impedance mismatch between traditional databases and vector stores-a problem the original LSM-Tree paper implicitly solved by demonstrating that arbitrary data types could be indexed efficiently through deferred updates. Similarly, Qdrant’s 1.8 release introduced “batched flushes” for vector data, explicitly citing the LSM-Tree as inspiration for reducing write amplification during high-frequency indexing.
The implications for AI infrastructure are profound. As models grow larger and context windows expand, the pressure on embedding stores to keep up with real-time updates will only increase. The LSM-Tree’s ability to decouple ingestion from indexing-allowing writes to proceed at memory speed while compaction proceeds in the background-makes it uniquely suited for this role. Whether in vector databases, agentic systems, or inference caches, the paper’s core insight remains: the most scalable path forward is not to optimize for immediate consistency, but to embrace deferred durability as a feature, not a bug. This approach has enabled systems to scale ingestion to rates that would overwhelm traditional B-tree-based architectures, proving the LSM-Tree’s enduring relevance in an era dominated by AI workloads.
Further reading
- Apache Cassandra documentation on SSTables and compaction: https://cassandra.apache.org/doc/latest/cassandra/architecture/storage-engine.html
- ScyllaDB engineering blog on LSM-Tree optimizations: https://www.scylladb.com/2023/05/15/compaction-deep-dive/
- ClickHouse MergeTree documentation: https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/mergetree
- Original LSM-Tree paper (PDF): https://www.cs.umb.edu/~poneil/lsmt.pdf
- Hybrid memory-disk systems and the CAP theorem - shows how consistency trade-offs in LSM-Trees relate to distributed guarantees
- Amazon Dynamo’s use of log-structured storage - highlights the influence of log-structured ideas on distributed systems design
- RocksDB documentation on compaction strategies: https://github.com/facebook/rocksdb/wiki/Compaction
- Pinecone engineering blog on vector indexing at scale: https://www.pinecone.io/learn/vector-indexing/