Timestamps in Message-Passing Systems That Preserve the Partial Ordering
Why this paper matters
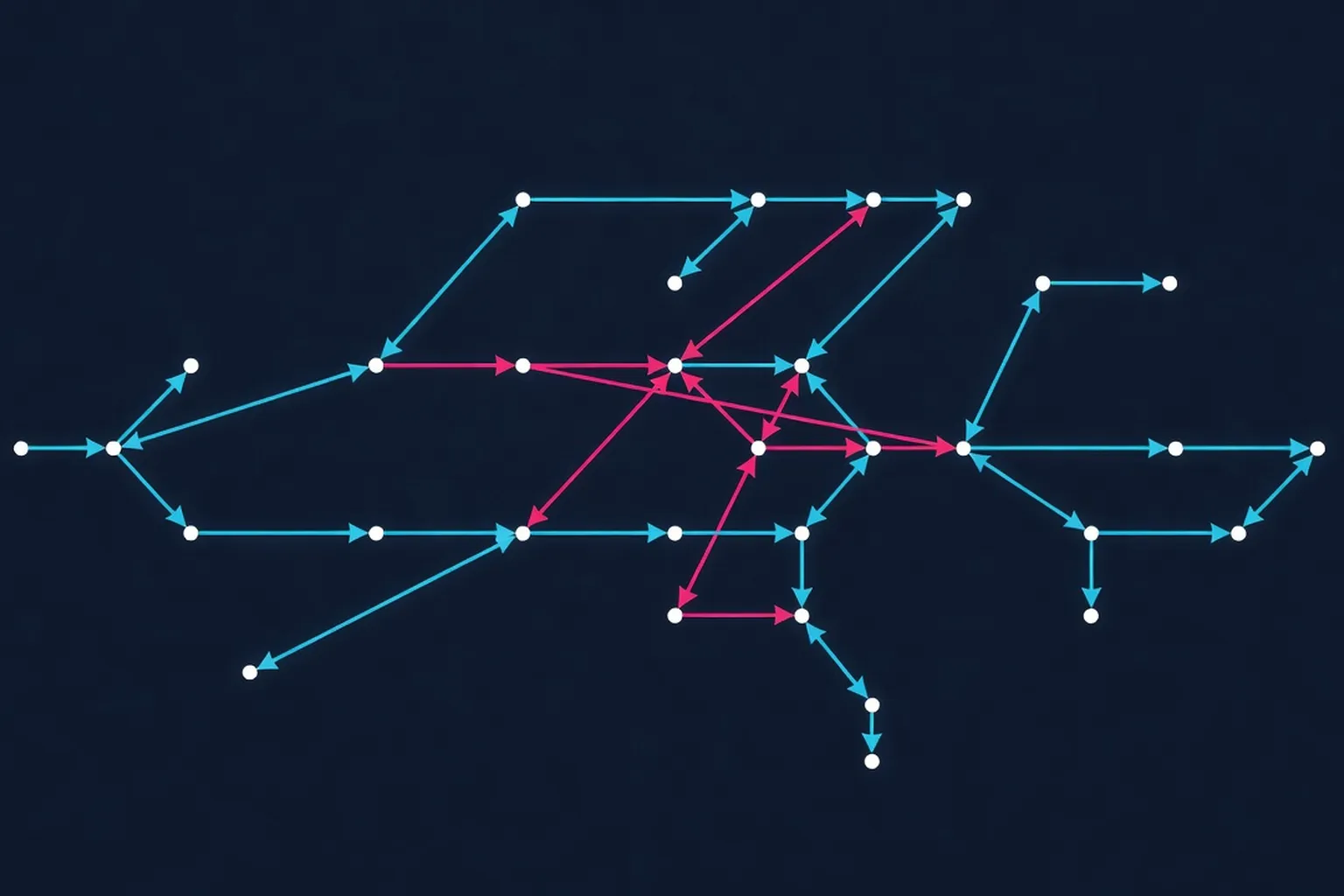
Fidge and Mattern’s 1989 paper introduces a fundamental shift in how distributed systems model causality by preserving the partial ordering of events rather than enforcing a total order. While Lamport’s 1978 logical clocks provided a simple mechanism for total ordering via the happened-before relation, they failed to capture the rich structure of concurrent executions where events may be causally independent. This paper addresses a critical gap by developing vector timestamps that explicitly encode the partial order of events in message-passing systems, enabling applications to reconstruct the true causal dependencies without centralized coordination. Historically, this work laid the groundwork for subsequent research in vector clocks, happened-before tracking, and causal consistency models that dominate modern distributed systems.
In 2026, the paper’s influence persists because partial ordering is now a first-class concern in systems where consistency and correctness must coexist with availability and partition tolerance. Modern distributed databases like Spanner and FoundationDB rely on variants of these timestamping techniques to implement snapshot isolation and conflict resolution without sacrificing performance at scale. The algorithms presented here directly inform how systems like Spanner handle external consistency by tracking causal dependencies across shards, while FoundationDB uses vector-like structures to maintain causal history for conflict-free replicated data types (CRDTs). The paper’s rejection of centralized timestamp authorities also anticipates modern decentralized designs, where vector clocks enable peer-to-peer causality tracking in systems like blockchain and edge computing networks. Its theoretical contributions remain indispensable in an era where distributed systems must balance strict correctness guarantees with real-world latency and fault tolerance constraints.
The paper also matters because it bridges the gap between theory and practice in systems where total order is either impossible or undesirable. Before Fidge and Mattern, engineers had to choose between weak consistency models or expensive global synchronization. Their work demonstrated that partial orderings could be tracked efficiently, paving the way for systems that prioritize availability and partition tolerance without sacrificing correctness. This paradigm shift is evident in today’s cloud-native architectures, where microservices and serverless functions rely on causal tracking to maintain consistency across thousands of nodes. Without the principles formalized in this paper, systems like Kubernetes’ etcd or HashiCorp’s Consul would struggle to provide linearizable reads and writes at internet scale.
Key contributions
- Formalization of vector timestamps as a mechanism to preserve the partial ordering of events in both synchronous and asynchronous message-passing systems, eliminating the need for total ordering where inappropriate.
- Algorithms for generating and comparing vector timestamps that capture the causal dependencies between events without requiring a central timestamping authority or modification to the communication graph.
- Proof of correctness demonstrating that vector timestamps can reconstruct the happened-before relation while avoiding the false causalities introduced by Lamport’s scalar clocks.
- Adaptation of the approach to handle synchronous systems, where message delivery is bounded, providing a unified framework for timestamping across different consistency models.
- Demonstration of how vector timestamps enable efficient access to the partial state of a distributed system, a prerequisite for applications requiring global state without global synchronization.
Impact on modern systems
Modern distributed databases have operationalized Fidge and Mattern’s vector timestamps to solve problems that were intractable under total-order models. Spanner, Google’s globally distributed database released in 2012 and now a cornerstone of Cloud Spanner, leverages vector-like causality tracking to implement external consistency. When a transaction commits in Spanner, it receives a timestamp that reflects not just wall-clock time but also the causal dependencies across all participating Paxos groups. This ensures that if transaction A causally precedes transaction B, A’s commit timestamp is strictly less than B’s, even across wide-area networks. Spanner’s TrueTime API, combined with vector timestamps, allows it to guarantee external consistency with an average commit latency of 10-20ms, a critical performance metric for globally distributed workloads. The vector timestamps here are abstracted as commit timestamps with causal ordering baked into the timestamp selection algorithm, directly derived from the partial-ordering principles in this paper.
FoundationDB, an open-source distributed transactional key-value store acquired by Apple and widely used in production since 2018, uses a variant of vector clocks to implement its ACID guarantees across hundreds of machines. Each database process maintains a vector clock that tracks the highest version vector seen from every other process. When a transaction is proposed, it carries this vector, ensuring that commit decisions respect causal order. FoundationDB’s adoption of vector clocks enables it to support multi-key transactions with strong consistency at scale, a design choice that traces back directly to the methods formalized by Fidge and Mattern. The system avoids Lamport clocks’ ambiguity by using vector timestamps to detect concurrent updates and resolve conflicts using deterministic transaction IDs, a technique that would be impossible without preserving partial order.
The influence extends beyond transactional systems. Distributed message queues like Apache Kafka use vector-like causality tracking in their log compaction and consumer offset management to ensure that consumers can reconstruct the state of the system at any point in time without relying on total order. Kafka’s design ensures that if a message is produced after another in the same partition, its offset reflects the causal dependency-an idea that mirrors the vector timestamping approach. Similarly, distributed consensus systems such as etcd rely on vector clocks in their Raft implementations to detect stale reads and ensure linearizability without a global sequencer.
The paper also underpins modern causal consistency models, such as those in YugabyteDB, a PostgreSQL-compatible distributed SQL database released in 2019. YugabyteDB implements causal consistency as a first-class API, allowing applications to read from follower nodes without violating causality. This is achieved by attaching vector timestamps to each row version and using them to prune the version history when serving stale reads. The process group approach to reliable distributed computing, published in 1991, further solidifies the theoretical foundation for these implementations, showing how group membership and failure detection can be integrated with vector-based causality.
Finally, vector timestamps inform the design of modern CRDTs, where the absence of a central authority makes partial-ordering essential. Systems like Redis with RedisJSON or TiDB use vector-like metadata to track the causal history of updates across replicas, enabling conflict-free merges without coordination. These applications demonstrate that Fidge and Mattern’s 1989 algorithms are not relics of theory but active components in the stack of 2026 production systems. Even the CAP theorem implicitly relies on causal ordering: a system that chooses availability over consistency must still respect the partial order of events to avoid inconsistency.
The impact is also visible in edge computing platforms like Akka Serverless, which uses vector clocks to synchronize state across globally distributed functions. By embedding vector timestamps in the event sourcing patterns of these systems, Akka Serverless ensures that updates are applied in causal order, even when network partitions occur. This design choice directly addresses the challenges outlined in the 1989 paper, proving its relevance in today’s serverless and edge-native architectures.
AI era: how LLMs and vector databases relate to this paper
The rise of large language models (LLMs) and vector databases has reintroduced the problem of partial ordering at an unprecedented scale. Vector databases like Pinecone, Weaviate, and Qdrant store high-dimensional embeddings that represent semantic relationships between data points. When an LLM generates a response using retrieval-augmented generation (RAG), it must respect the causal and semantic dependencies between the retrieved chunks. Here, Fidge and Mattern’s vector timestamps offer a formal way to model these dependencies, ensuring that the retrieval process respects the partial order of the user’s query context rather than treating all vectors as equally relevant.
In RAG systems, user queries are often decomposed into subqueries that may execute concurrently across multiple shards of a vector database. Each shard may return a set of candidate embeddings, but the final response must reflect the causal flow of the user’s intent. For example, if a user asks ‘What was the impact of the 2008 financial crisis on European banks?’, the system must first retrieve information about the crisis, then about European banks, and finally synthesize the relationship. Vector timestamps can be attached to each retrieved embedding to indicate its position in this causal chain. When merging results, the system can use vector comparison to prioritize embeddings that are causally downstream of earlier retrievals, avoiding out-of-order or irrelevant context. This mirrors the partial-ordering principle: not all retrieved data is equally relevant; only that which respects the query’s causal flow should influence the response.
LLM inference engines increasingly maintain state across multiple turns of conversation, forming a distributed execution graph where each token generation depends on prior context. Vector timestamps can annotate this state, enabling the system to detect stale or out-of-order updates when multiple agents or tools write concurrently. For instance, in an AI agent system where one agent fetches financial data while another queries regulatory filings, the final state must reflect the causal dependency between these operations. By attaching vector timestamps to each state update and using the happened-before relation to merge states, the system avoids hallucinations caused by inconsistent state views-a direct application of the paper’s methods.
Vector databases themselves can implement causal consistency using vector timestamps. Systems like pgvector (PostgreSQL’s vector extension) and Milvus now support transactional semantics where embeddings are updated with causal metadata. When a new embedding is inserted or updated, it carries a vector timestamp that reflects the causal dependencies of the underlying data. Queries can then filter or reorder results based on this timestamp, ensuring that stale embeddings do not contaminate the retrieval process. For example, if a document is modified after an embedding is generated, the new embedding will have a higher timestamp, and queries can use vector comparison to select the most recent version. This approach reduces the need for expensive global synchronization while maintaining correctness.
The paper’s influence extends to LLM-driven query planning. Modern query planners, such as those in TiDB or CockroachDB, use vector embeddings to represent SQL queries and their semantic relationships. When planning a distributed query, the planner must respect the partial order of operations: a join cannot proceed before its inputs are available, and filters must be applied in an order that respects data dependencies. By attaching vector timestamps to each planning step, the system can detect and resolve conflicts in the query graph, ensuring that the final execution plan respects the causal structure of the user’s intent. This is particularly critical in AI-generated SQL, where the planner must avoid nonsensical or unsafe execution orders.
Finally, the AI era has resurrected the problem of global state in distributed systems. Vector databases used for semantic search now double as state stores for AI agents, where the state evolves through a series of causally dependent operations. Fidge and Mattern’s algorithms provide a formal foundation for managing this state without global locks. For example, a multi-agent system where agents collaborate on a document can use vector timestamps to track which agent made which change and in what causal order. This enables efficient conflict resolution and rollback without requiring a central coordinator-a key advantage in systems where latency and availability are paramount. The integration of vector timestamps into these systems is not merely theoretical; it is a practical necessity for building reliable, scalable AI infrastructure in 2026.
The connection between vector timestamps and embeddings is not coincidental. Both represent high-dimensional state that must be ordered causally. In systems like Amazon DynamoDB, which underpins many AI services, vector-like metadata is used to track the causal history of items in the LSM-tree storage engine. This allows DynamoDB to support conditional writes and transactions while maintaining performance, a direct echo of the partial-ordering principles from 1989. Similarly, Google Bigtable’s timestamp-based versioning, while simpler than vector clocks, shares the same goal: to preserve the causal relationship between updates without imposing a total order.
Further reading
- Original paper (PDF) - Fidge’s technical report with full algorithmic details and proofs.
- Vector Clocks in Distributed Systems (MIT Lecture Notes) - Practical overview of vector clock usage in modern systems.
- Causal Consistency in Distributed Databases (CACM, 2019) - Survey of causal consistency models inspired by this work.
- Spanner: Becoming the SQL Engine of the World’s Largest Companies (Google Cloud Blog, 2023) - Discusses TrueTime and vector-like timestamps in production.
- FoundationDB: A Distributed Unbundled Transactional Key-Value Store (ACM Queue, 2020) - Covers vector clocks in transactional systems.
- Eventually Consistent (ACM Queue, 2009) - Explores how causal consistency fits into the broader landscape of distributed systems trade-offs.