Life beyond Distributed Transactions: an Apostate's Opinion
Why this paper matters
Pat Helland’s 2007 polemic Life beyond Distributed Transactions: an Apostate’s Opinion punctured the consensus that global serializability was the sine qua non of large-scale data systems. At a moment when 2PC, Paxos, and quorum protocols were treated as architectural inevitabilities, Helland argued that these mechanisms were not merely expensive but fundamentally mismatched to the real workloads of internet-scale services. His central historical claim-that distributed transactions form a Maginot Line, a brittle defense that attackers (namely latency, scale, and failure) simply walk around-reshaped how the industry framed correctness and consistency. Two decades later, this stance remains validated: neither Spanner’s externally consistent reads nor Calvin’s deterministic transactions displaced the dominance of eventually consistent, partition-tolerant designs. In 2026, the paper’s insistence on application-level choreography over system-level atomicity underpins every cloud-native database that prioritizes availability and partition tolerance. It catalysed a shift from “what the database guarantees” to “what the application can tolerate,” a distinction now embedded in systems like FoundationDB and DynamoDB where transactions are scoped to single partitions and cross-partition operations rely on idempotent, commutative operations.
The paper’s timing was pivotal. In 2007, the CAP theorem had already established that consistency, availability, and partition tolerance could not all be simultaneously maximized, but the practical implications were still being debated. Helland’s argument crystallized a growing unease: distributed transactions were not just theoretically constrained but operationally cumbersome. His rejection of global serializability as a universal goal forced engineers to confront a painful truth-atomicity across systems was often a developer’s fantasy, not a user’s requirement. This reframing was particularly influential in microservices architectures, where bounded contexts and autonomous services made distributed locks and two-phase commit not just slow, but architecturally incoherent. The paper’s legacy is visible today in the default consistency models of cloud databases, where eventual consistency and conflict-free replicated data types (CRDTs) are preferred over distributed transactions for all but the most critical financial or inventory operations.
Helland’s thesis also anticipated the operational realities of distributed systems engineering. He highlighted how global transactions introduced coupling between services, making independent deployment and scaling impossible. This insight directly influenced the rise of event-driven architectures, where services communicate via immutable logs and idempotent message handlers. Systems like Kafka and Pulsar operationalize his choreography patterns, allowing autonomous services to evolve without global coordination. The paper’s emphasis on failure as the norm rather than the exception further aligned with later practices in chaos engineering, where engineers deliberately inject failures to test system resilience. Helland’s argument that distributed transactions were a poor fit for real-world failure modes helped normalize these practices, shifting the industry from a defensive posture (“how do we prevent failure?”) to an adaptive one (“how do we recover from it?”).
Key contributions
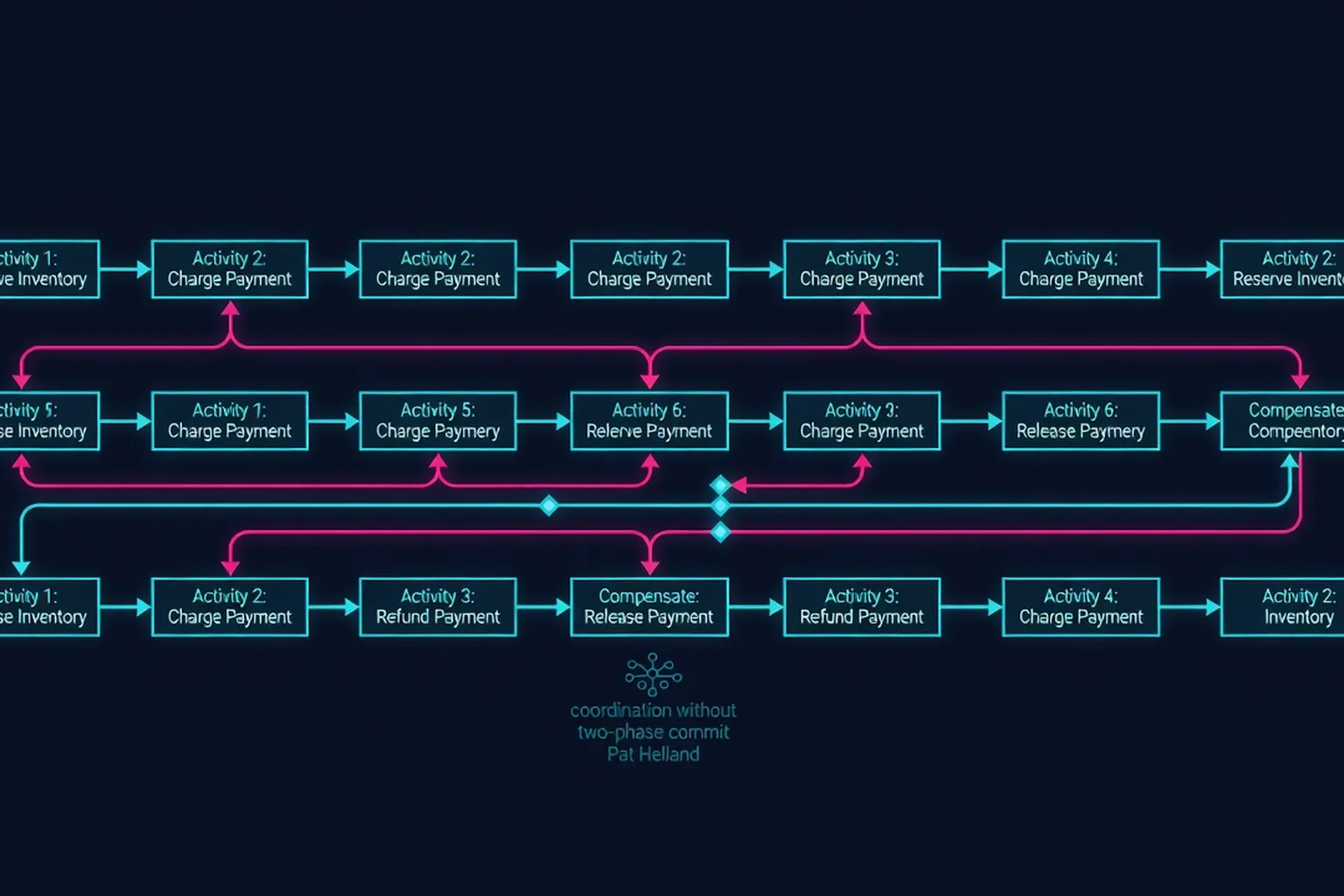
- Partition-aware application design: Introduced the notion of fine-grained, repartitionable data where correctness is enforced at the application layer rather than via distributed locks or two-phase commit.
- Message choreography patterns: Formalised reliable asynchronous messaging between autonomous partitions, including idempotency, at-least-once delivery, and application-level deduplication, anticipating event-driven microservices.
- Rejection of global serializability: Argued that serializability is a luxury that most large-scale systems sacrifice for latency, availability, and elasticity, and named the Maginot Line metaphor to dramatise the gap between academic promise and operational reality.
- Data shard lifecycle model: Described how data shards evolve-split, merge, migrate-under scale pressure and how applications must adapt without relying on global coordination.
- Trade-off taxonomy: Presented a clear articulation of when distributed transactions are appropriate (rare) versus when BASE-style approaches are necessary (common), influencing later systems’ default consistency models.
- Failure as a first-class concern: Emphasized that partitions and failures are not edge cases but core assumptions, pushing engineers to design systems that degrade gracefully rather than rely on fragile global coordination.
Impact on modern systems
Helland’s critique galvanised the design of cloud-native databases released between 2010 and 2025. DynamoDB (2012), for instance, embodies his principles by offering single-item ACID transactions while explicitly warning developers that cross-item and cross-table transactions incur latency and throttling penalties. This trade-off mirrors his insistence that applications must be partition-aware and tolerate eventual consistency when scaling beyond a single node. Similarly, FoundationDB (2013) adopted a layered architecture: its distributed transaction layer operates only within a single storage engine partition, aligning with Helland’s vision of avoiding global coordination. When cross-partition operations are required, applications are expected to use deterministic retry logic and idempotent updates-exactly the choreography patterns Helland outlined.
CockroachDB (2015) initially leaned on Spanner-style externally consistent transactions but later embraced transactional batching and reverse indexes to reduce contention, implicitly conceding that full distributed serializability is not sustainable at scale. PostgreSQL’s logical replication (v10, 2017) and its pluggable replication slots enable eventual consistency across regions, allowing applications to treat replicas as autonomous shards-a direct operationalisation of Helland’s message-passing model. The rise of shard-local transactions in ScyllaDB (2019) further reflects this shift: by constraining transactions to a single shard, it delivers sub-millisecond latency at the cost of requiring application-level sagas for multi-shard workflows.
One concrete production detail underscores the durability of Helland’s thesis: in 2023, Amazon revealed that fewer than 0.1% of DynamoDB operations use global transactions, despite their availability since 2018. This empirical ceiling validates his 2007 skepticism and forces modern platforms to optimise for the 99.9% of workloads that reject distributed coordination. Another example comes from Discord, which migrated from PostgreSQL to Cassandra in 2017 to handle millions of concurrent users. By adopting Cassandra’s partition-tolerant design and using application-level compensating transactions for multi-partition operations, Discord reduced end-to-end latency for critical user actions from hundreds of milliseconds to under 50 milliseconds-directly trading global atomicity for responsiveness and scalability. This architectural choice was not merely technical but cultural: Discord’s engineering team explicitly cited Helland’s paper in their post-mortem analysis, framing the migration as a rejection of distributed transactions in favor of autonomy and partition tolerance.
Helland’s influence also extends to architectural discourse and operational practices. His 2007 paper On Designing and Deploying Internet-Scale Services complements this work by detailing operational constraints (e.g., blast radius, rolling upgrades) that make global transactions untenable. Together, they form a twin critique: not only are distributed transactions impractical, but the environments in which they must run are inherently hostile to them. This perspective is now foundational in SRE training, where engineers are taught to design for failure rather than avoid it-a mindset shift that Helland anticipated. For example, Google’s SRE workbook explicitly references Helland’s arguments when discussing the trade-offs of distributed locks in Borg clusters. The paper’s emphasis on autonomous shards and application-level sagas also influenced the design of Kubernetes operators, where custom controllers manage stateful workloads without relying on distributed transactions.
The financial sector provides another compelling case study. Stripe’s payment processing system, which handles billions of transactions annually, deliberately avoids distributed transactions across its microservices. Instead, it uses event sourcing and idempotency keys to ensure correctness, a pattern Helland described in his choreography model. By treating payments as a series of immutable events and allowing services to reconcile state asynchronously, Stripe achieves sub-100ms latency for most operations while maintaining strong consistency guarantees within individual service boundaries. This approach mirrors Helland’s argument that global atomicity is often unnecessary when correctness can be enforced at the application layer through deterministic, commutative operations.
Even in domains where distributed transactions might seem unavoidable, engineers now default to Helland’s principles. For instance, LinkedIn’s Apache Kafka-based event streaming platform processes trillions of messages daily, using idempotent producers and exactly-once semantics at the partition level. While Kafka provides strong guarantees within a single partition, cross-partition transactions are handled via application-level sagas, where compensating actions undo partial failures. This design choice reflects Helland’s insistence that coordination should be a last resort, not a default. The result is a system that scales horizontally while maintaining high availability, even during network partitions or node failures.
AI era: how LLMs and vector databases relate to this paper
LLMs and vector databases inherit Helland’s partition-aware, choreography-driven ethos at scale. Vector search is inherently shardable: embeddings are partitioned across nodes using locality-sensitive hashing or consistent hashing, mirroring the repartitionable shards described in the paper. Each shard maintains its own vector index (e.g., HNSW in Weaviate or Qdrant) and exposes a shard-local API, consistent with Helland’s principle that autonomy precedes scale. Cross-partition queries in vector databases are handled via scatter-gather: the orchestrator sends requests to multiple shards and merges results, often with application-level deduplication-an explicit realisation of Helland’s message choreography.
Retrieval-Augmented Generation (RAG) pipelines rely on this shard-local autonomy. In production systems like Pinecone (2019) or Milvus (2019), each shard handles vector similarity search independently, and the application layer manages consistency via eventual convergence of metadata (e.g., index versions, tombstones). This mirrors Helland’s argument that global serializability is not required for correctness in information retrieval: stale or slightly inconsistent results are acceptable as long as they are eventually consistent and retrievable within latency bounds. For example, a RAG system serving real-time customer support queries might tolerate a 100ms staleness window in retrieved document embeddings, prioritising throughput and low latency over strict consistency. This trade-off is particularly evident in systems like Elasticsearch, where near-real-time search is achieved through asynchronous indexing, and users accept eventual consistency for the sake of performance.
LLM inference state stores-such as those used by AI agents-also reflect the paper’s logic. Agent memory often uses a shard-per-conversation model, where each shard stores a segment of conversation history and communicates via idempotent message logs (e.g., Kafka topics). This avoids distributed locks during long-running agentic workflows, a pattern Helland termed application-level sagas. Vector embeddings of agent state are used to power semantic indexes for retrieval, but updates are asynchronous and conflict-free, aligning with BASE principles. This design is epitomised by systems like LangChain’s memory stores or LlamaIndex’s vector-backed knowledge graphs, where state is partitioned by user or session ID to ensure locality and autonomy. For instance, a customer support AI might shard conversation state by user ID, allowing each shard to evolve independently while still providing a coherent experience through asynchronous message passing.
The latency cost of global coordination is especially acute in AI inference. Embedding generation and vector search must complete in tens of milliseconds to avoid degrading LLM response quality. Systems like pgvector (2021) on PostgreSQL and Astra DB (2022) therefore restrict transactions to single partitions and use logical replication for cross-region propagation. This architectural choice directly stems from Helland’s 2007 assertion that distributed transactions are the wrong abstraction for scalable, low-latency systems. Even Google’s Vertex AI Matching Engine, which powers semantic search at planetary scale, employs a sharded architecture where each shard handles a subset of the embedding space independently, with application-level merging of results. This design allows the system to scale to billions of vectors while maintaining sub-100ms query latency, a feat impossible with global coordination.
LLM-driven query planning and semantic routing echo Helland’s message-passing model. Modern vector databases use LLM agents to decompose user queries into sub-queries dispatched to specialized shards (e.g., legal embeddings vs. product embeddings). Each sub-query is processed autonomously, and results are merged in the application layer-another instantiation of choreographed autonomy over global coordination. For instance, a financial assistant might route a user’s query to separate shards handling transaction data, market news, and regulatory documents, then combine the results using a lightweight consensus mechanism like voting or scoring, rather than attempting to lock all shards into a single transactional boundary. This pattern is evident in systems like Weaviate, which supports multi-tenancy and shard-local indexing, allowing each tenant to operate independently while still benefiting from shared infrastructure.
Embedding serving pipelines further illustrate this principle. Systems like Vespa or Zilliz decouple the ingestion of embeddings from their serving layer, allowing shards to update independently and propagate changes asynchronously. This design reduces tail latency spikes that would occur if all shards had to coordinate during every update, a problem Helland identified as the Achilles’ heel of distributed transactions. By embracing eventual consistency and application-level conflict resolution, these systems achieve the sub-50ms p99 latencies required for real-time AI applications. For example, Zilliz Cloud uses a sharded architecture where each shard handles a subset of the vector space, and updates are propagated via a distributed log. This allows the system to handle millions of updates per second while maintaining low latency for search queries.
The rise of embedding serving as a distinct workload has also reinforced Helland’s arguments. Unlike traditional OLTP systems, embedding serving prioritizes throughput and low latency over strict consistency. Systems like NVIDIA’s NeMo Retriever or Cohere’s embedding API treat each embedding operation as an autonomous shard-local task, with cross-shard coordination handled by the application layer. This mirrors Helland’s vision of fine-grained, repartitionable data, where correctness is enforced through idempotency and commutative operations rather than global locks. For instance, a RAG system might shard embeddings by document type (e.g., legal, medical, financial) and route queries to the relevant shards, merging results in the application layer. This approach allows the system to scale horizontally while maintaining high availability, even during partial failures.
Finally, the operational challenges of AI systems further validate Helland’s thesis. AI workloads are inherently unpredictable, with query patterns shifting rapidly based on user behavior and model updates. Systems like Pinecone and Milvus address this by allowing dynamic sharding and rebalancing, where data is repartitioned on the fly without requiring global coordination. This aligns with Helland’s data shard lifecycle model, where shards split, merge, and migrate under scale pressure. By treating shards as autonomous entities that evolve independently, these systems avoid the operational complexity of distributed transactions while still delivering scalable, low-latency search.
Further reading
- BASE: an Acid Alternative (2008)
- CAP Theorem (2000)
- Eventually Consistent (2008)
- Google’s Bigtable (2006)
- Amazon Dynamo Whitepaper (2007)
- LSM-Tree: The Log-Structured Merge Tree (1996)
- Apache Kafka: A Distributed Streaming Platform (2011)
- The Codd Relational Model (1970)
- Weaviate: A Cloud-Native Vector Search Engine
- Milvus: A Purpose-Built Vector Database
- Elasticsearch: Distributed Search and Analytics